

SQL কনস্ট্রেইন্ট(Constraints) একটি টেবিলের ডেটা কলামগুলির উপর নিয়ম আরোপ করতে ব্যবহৃত হয়। এটি একটি টেবিলে ইনপুটকৃত তথ্যের সীমা নির্ধারন করতে পারে। এটি ডেটাবেজ তথ্যের সঠিকতা এবং নির্ভরযোগ্যতা নিশ্চিত করে।
কনস্ট্রেইন্ট(constraint) কর্তৃক আরোপিত সীমা লংঘনকারী সকল কর্মকান্ডকে কনস্ট্রেইন্ট বাধা দেয়।
SQL এ Constraints সমূহঃ
NOT NULL - একটি কলামে NULL ভ্যালু থাকতে পারবে না।UNIQUE - একটি কলামের প্রতিটি সারিতে ইউনিক ভ্যালু থাকবে।PRIMARY KEY - ইহা NOT NULL এবং UNIQUE এর সংমিশ্রণ।FOREIGN KEY - দুইটি টেবিলের মধ্যে সংযোগ সৃষ্টি করে।CHECK- একটি টেবিলের প্রতিটি সারিতে একটি শর্ত আরোপ করে।DEFAULT - একটি কলামের জন্য ডিফল্ট ভ্যালু নির্দিষ্ট করে।টেবিল তৈরি করার সময়ে আমরা Constraints সেট করতে পারি। এছাড়া পূর্বের তৈরি টেবিলেও Constraints যোগ করতে পারি।
CREATE TABLE name_of_table
(
name_of_column_1 data_type(size) name_of_constraint,
name_of_column_2 data_type(size) name_of_constraint,
....
);
ALTER TABLE name_of_table DROP CONSTRAINT name_of_constraint;Join এর বাংলা অর্থ কোন কিছু একত্রিত করা। SQL -এ JOIN দুই বা ততোধিক টেবিলকে একত্রিত করে।
একটি ডেটাবেজ দুই বা ততোধিক টেবিলের কলাম ফিল্ডের উপর ভিত্তিকরে যথাক্রমে দুই বা ততোধিক টেবিল থেকে সারি নিয়ে তাদের একত্রিত করার জন্য SQL JOIN clause ব্যবহৃত হয়।
নিম্নে JOIN সমূহের তালিকা ও ব্যবহার তুলে ধরা হলোঃ
INNER JOIN - উভয় টেবিলে অন্তত একটি কলামের মিল থাকলে সকল সারি রিটার্ন করে।LEFT JOIN - ডান টেবিলের মিলিত সারিসহ বাম টেবিলের সকল সারি রিটার্ন করে।RIGHT JOIN - বাম টেবিলের মিলিত সারিসহ ডান টেবিলের সকল সারি রিটার্ন করে।FULL JOIN -যেকোনো একটি টেবিলের সাথে মিল থাকলে উভয় টেবিলের সকল সারি রিটার্ন করে।CROSS JOIN - বাম পাশের মিলিত সারির একটি কলামের জন্য ডান পাশের মিলিত সারির প্রতিটি কলামকে রিটার্ন করে।
SQL এর সবচেয়ে সাধারণ JOIN হলোঃ SQL INNER JOIN।join এর সাধারণ সর্ত পুরণ হলে SQL INNER JOIN একাধিক টেবিল থেকে সারি রির্টান করে।
JOIN কীওয়ার্ডের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়াঃ
| রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|
| ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ১০২ | ৯১ | ০১-১১-২০১৫ |
| ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ১০৫ | ৭৭ | ০২-১১-২০১৫ |
উপরের টেবিল দুটিতে লক্ষ্য করলে দেখবেন যে, "রোল নাম্বার(Roll_number)" কলামটি উভয় টেবিলে রয়েছে। "Student_details" টেবিলের "রোল নাম্বার(Roll_number)" কলামটি "Student_attendance" টেবিলের "রোল নাম্বার(Roll_number)" কলামকে নির্দেশ করে। "রোল নাম্বার(Roll_number)" কলামটি উভয় টেবিলের মধ্যে সম্পর্ক তৈরি করছে।
SELECT Student_attendance.Roll_number, Student_details.Student_name, Student_attendance.Admission_date
FROM Student_attendance INNER JOIN Student_details
ON Student_attendance.Roll_number=Student_details.Roll_number;
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
| ১০২ | মিনহাজুর রহমান | ০১-১১-২০১৫ |
| ১০৩ | মোঃ সবুজ হোসেন | ০১-১১-২০১৫ |
| ১০৪ | ইয়াসিন হোসেন | ০২-১১-২০১৫ |
| ১০৫ | ফরহাদ উদ্দিন | ০২-১১-২০১৫ |
Join এর সবচেয়ে গুরুত্বপূর্ণ এবং সর্বাধিক ব্যবহৃত ধরন হচ্ছে INNER JOIN। দুই বা ততোধিক টেবিলের কলামের ভ্যালু গুলোকে একত্রিত করার মাধ্যমে INNER JOIN একটি নতুন টেবিল তৈরি করে।
কুয়েরী করার সময় ON কীওয়ার্ড ের মাধ্যমে শর্ত জুড়ে দেওয়া হয়। যখন ঐ শর্ত বা শর্ত-সমূহ পূর্ণ হয় তখন উভয় টেবিলের তথ্য গুলো একত্রিত হয়ে একটি ফলাফল টেবিল তৈরি হয়।
SELECT name_of_column's
FROM first_table
INNER JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
অথবাঃ
SELECT name_of_column's
FROM first_table
JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
মনে রাখবেন, INNER JOIN এবং JOIN একই অর্থে ব্যবহৃত হয়।
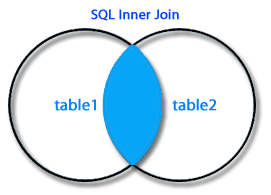
JOIN কীওয়ার্ডের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়াঃ
| রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|
| ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ১০২ | ৯১ | ০১-১১-২০১৫ |
| ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ১০৫ | ৭৭ | ০২-১১-২০১৫ |
নিম্নের SQL স্টেটমেন্টটি সকল শিক্ষার্থীর নামের সাথে তাদের ভর্তির তারিখ ফেরত দিবেঃ
SELECT Student_attendance.Roll_number, Student_details.Student_name, Student_attendance.Admission_date
FROM Student_attendance INNER JOIN Student_details
ON Student_attendance.Roll_number=Student_details.Roll_number;
বিঃদ্রঃ উভয় টেবিলের যেসকল কলামের তথ্য গুলো ম্যাচ করবে INNER JOIN শুধুমাত্র ঐ সকল সারি গুলোকে একত্রিত করে ফলাফল দেখাবে।
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
| ১০২ | মিনহাজুর রহমান | ০১-১১-২০১৫ |
| ১০৩ | মোঃ সবুজ হোসেন | ০১-১১-২০১৫ |
| ১০৪ | ইয়াসিন হোসেন | ০২-১১-২০১৫ |
| ১০৫ | ফরহাদ উদ্দিন | ০২-১১-২০১৫ |
SQL LEFT JOIN কীওয়ার্ডটি বাম টেবিলের(first_table) সকল সারিকে এবং ডান টেবিলের(second_table) শুধুমাত্র সদৃশ(matched) সারি গুলোকে একত্রিত করে ফলাফল-টেবিলে ফলাফল রিটার্ন করে। যদি সদৃশ কিছু খুঁজে না পায় তাহলে ডান টেবিল থেকে কোনো কিছু কুয়েরি/রিটার্ন করবে না।
SELECT name_of_column's
FROM first_table
LEFT JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
অথবাঃ
SELECT name_of_column's
FROM first_table
LEFT OUTER JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
কিছু ডেটাবেজে LEFT JOIN কে LEFT OUTER JOIN বলা হয়ে থাকে।
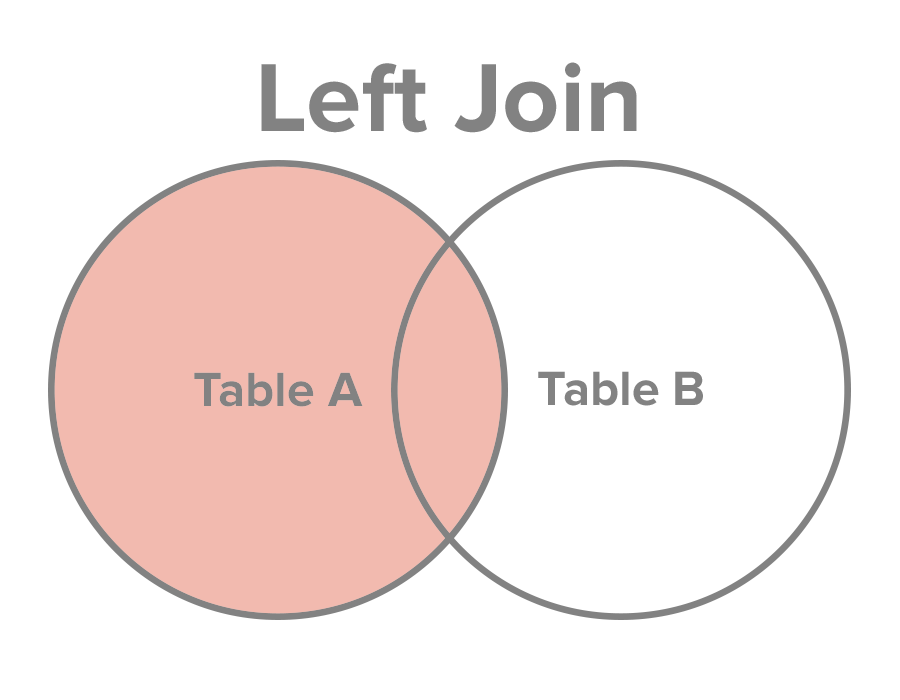
LEFT JOIN কীওয়ার্ডের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_result" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | ফলাফল |
|---|---|
| ১০১ | A+ |
| ১০২ | A+ |
| ১০৩ | A+ |
| ১০৪ | A+ |
| ১০৫ | A+ |
নিম্নের SQL স্টেটমেন্টটি সকল শিক্ষার্থীর তথ্য রিটার্ন করবে এবং যদি তাদের পরীক্ষার ফলাফল থাকে তবে তাও রিটার্ন করবেঃ
SELECT Student_details.Student_name ,Student_details.Roll_number, Student_result.Result
FROM Student_details
LEFT JOIN Student_result
ON Student_details.Roll_number=Student_result.Roll_number
ORDER BY Student_details.Student_name;
বিঃদ্রঃ ডান টেবিলের মধ্যে সদৃশ(matched) কোনো কিছু খুঁজে না পেলেও LEFT JOIN কীওয়ার্ড টি বাম টেবিলের সকল সারি রিটার্ন করবে।
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ফলাফল |
|---|---|---|
| ১২৩ | আসমা আক্তার | A- |
| ১০৪ | ইয়াসিন হোসেন | A+ |
| ১২৮ | উম্মে কুলসুম | B |
| ১১৪ | ওমর ফারুক | A |
| ১০৯ | ওয়াহিদুল ইসলাম | A |
SQL RIGHT JOIN কীওয়ার্ডটি ডান টেবিলের(second_table) সকল সারিকে এবং বাম টেবিলের(first_table) শুধুমাত্র সদৃশ(matched) সারি গুলোকে একত্রিত করে ফলাফল-টেবিলে ফলাফল রিটার্ন করে। যদি সদৃশ কিছু খুঁজে না পায় তাহলে বাম টেবিল থেকে কোনো কিছু কুয়েরি/রিটার্ন করবে না।
SELECT name_of_column's
FROM first_table
RIGHT JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
অথবাঃ
SELECT name_of_column's
FROM first_table
RIGHT OUTER JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
কিছু ডাটাবেজে RIGHT JOIN কে RIGHT OUTER JOIN বলা হয়ে থাকে।
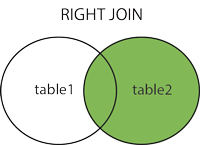
RIGHT JOIN কীওয়ার্ডের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|
| ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ১০২ | ৯১ | ০১-১১-২০১৫ |
| ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ১০৫ | ৭৭ | ০২-১১-২০১৫ |
নিম্নের SQL স্টেটমেন্টটি সকল শিক্ষার্থীর তথ্য রিটার্ন করবে এবং যদি তাদের ভর্তির তারিখ দেওয়া থাকে তবে তাও রিটার্ন করবেঃ
SELECT Student_details.Roll_number, Student_details.Student_name, Student_attendance.Admission_date
FROM Student_attendance
RIGHT JOIN Student_details
ON Student_details.Roll_number=Student_attendance.Roll_number
ORDER BY Student_attendance.Admission_date;
বিঃদ্রঃ বাম টেবিলের মধ্যে সদৃশ(matched) কোনো কিছু খুঁজে না পেলেও RIGHT JOIN কীওয়ার্ড টি ডান টেবিলের সকল সারি রিটার্ন করবে।
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
| ১০২ | মিনহাজুর রহমান | ০১-১১-২০১৫ |
| ১০৩ | মোঃ সবুজ হোসেন | ০১-১১-২০১৫ |
| ১০৪ | ইয়াসিন হোসেন | ০২-১১-২০১৫ |
| ১০৫ | ফরহাদ উদ্দিন | ০২-১১-২০১৫ |
FULL JOIN কীওয়ার্ডটি বাম(first_table) এবং ডান(second_table) উভয় টেবিলের সকল সারি রিটার্ন করে।
সুতরাং FULL JOIN কীওয়ার্ডটি LEFT JOIN এবং RIGHT JOIN এর ফলাফল গুলো একত্রিত করে। এক্ষেত্রে যদি কোনো ফলাফল না পায় তাহলে NULL ভ্যালু রিটার্ন করে।
SELECT name_of_column's
FROM first_table
FULL JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
অথবাঃ
SELECT name_of_column's
FROM first_table
FULL OUTER JOIN second_table
ON first_table.name_of_column=second_table.name_of_column;
কিছু ডেটাবেজে FULL JOIN কে FULL OUTER JOIN বলা হয়ে থাকে।
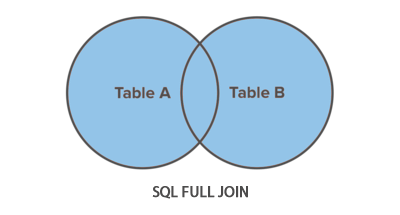
FULL JOIN কীওয়ার্ডের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|
| ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ১০২ | ৯১ | ০১-১১-২০১৫ |
| ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ১০৫ | ৭৭ | ০২-১১-২০১৫ |
নিম্নের SQL স্টেটমেন্টটি সকল শিক্ষার্থীর তথ্য গুলো একত্রিত করবেঃ
SELECT Student_details.Roll_number, Student_details.Student_name, Student_attendance.Admission_date
FROM Student_details
FULL JOIN Student_attendance
ON Student_details.Roll_number=Student_attendance.Roll_number
ORDER BY Student_details.Student_name;
ফলাফলটি কিছুটা এমন দেখাবেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
| ১০২ | মিনহাজুর রহমান | ০১-১১-২০১৫ |
| ১০৩ | মোঃ সবুজ হোসেন | ০১-১১-২০১৫ |
| ১০৪ | ইয়াসিন হোসেন | ০১-১১-২০১৫ |
| ১০৫ | ফরহাদ উদ্দিন |
বিঃদ্রঃ FULL JOIN কীওয়ার্ডটি বাম টেবিল(first_table) এবং ডান টেবিলের(second_table) সকল সারি রিটার্ন করবে। এক্ষেত্রে কোনো সদৃশ সারি না থাকলেও উভয় টেবিলের সকল সারি রিটার্ন করবে।
SQL UNION অপারেটরটি দুই বা ততোধিক SELECT স্টেটমেন্টের ফলাফল একত্রে প্রকাশ করতে পারে।
SQL UNION অপারেটরটি কোন ডুপ্লিকেট সারি ফেরত দেওয়া ছাড়াই দুই বা ততোধিক SELECT স্টেটমেন্টের ফলাফল একত্রিত করে।
UNION অপারেটর ব্যবহারের পূর্বশর্তঃ
SELECT স্টেটমেন্টে কলামের সংখ্যা অবশ্যই সমান থাকতে হবে।SELECT স্টেটমেন্টের সকল কলাম-সমূহ একই ক্রমে(order) থাকতে হবে।SELECT name_of_column's FROM first_table
UNION
SELECT name_of_column's FROM second_table;
বিঃদ্রঃ UNION অপারেটরটি ডিফল্টভাবে একাধিক ভ্যালু শুধুমাত্র একবার সিলেক্ট করে। ডুপ্লিকেট(Duplicate) ভ্যালু পাওয়ার জন্য UNION এর সাথে ALL কিওয়ার্ড ব্যবহার করতে হবে।
SELECT name_of_column's FROM first_table
UNION ALL
SELECT name_of_column's FROM second_table;
UNION এ ব্যবহৃত প্রথম স্টেটমেন্টের কলামের নাম ফলাফল টেবিলের কলামের নাম এর সমান হয়। সুতরাং প্রথম স্টেটমেন্টের কলামের নাম-ই ফলাফল টেবিলের কলামের নাম হয়।
UNION অপারেটরের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Teacher_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ঠিকানা |
|---|---|---|
| ১০৪ | ইয়াসিন হোসেন | |
| ১০৫ | ফরহাদ উদ্দিন | |
| ১০৯ | ওয়াহিদুল ইসলাম |
নিম্নের SQL UNION স্টেটমেন্টটি "Student_details" এবং "Teacher_details" টেবিল থেকে সকল "ঠিকানা(Address)" কলামকে সিলেক্ট করবে এবং শুধুমাত্র স্বতন্ত্র(Distinct) ভ্যালুগুলো নিয়ে আসবেঃ
SELECT Address FROM Student_details
UNION
SELECT Address FROM Teacher_details
ORDER BY Address;
বিঃদ্রঃ UNION অপারেটরটি দ্বারা "ঠিকানা(Address)" কলামের সকল ডেটা পাওয়া যাবে না। যদি এক বা একাধিক "শিক্ষার্থী" অথবা "শিক্ষক" এর শহর একই হয় তাহলে শহরটি একবার-ই দেখাবে। অপরপক্ষে UNION ALL ব্যবহার করলে সব গুলো শহরই একত্রে দেখাবে অর্থাৎ ডুপ্লিকেট ভ্যালু-সমূহও দেখাবে।
নিম্নের SQL UNION ALL স্টেটমেন্টটি "Student_details" এবং "Teacher_details" টেবিল থেকে সকল স্বতন্ত্র "ঠিকানা"-সহ ডুপ্লিকেট ঠিকানাও নিয়ে আসবেঃ
SELECT Address FROM Student_details
UNION ALL
SELECT Address FROM Teacher_details
ORDER BY Address;
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| আইডি | ঠিকানা |
|---|---|
| ১ | ঢাকা |
| ২ | রাজশাহী |
| ৩ | চাঁদপুর |
| ৪ | বরিশাল |
| ৫ | সিলেট |
নিম্নের SQL UNION ALL স্টেটমেন্টটি "Student_details" এবং "Teacher_details" টেবিল থেকে "ঢাকা" শহর বিশিষ্ট সকলের তথ্য(ডুপ্লিকেট ভ্যালুও) নিয়ে আসবেঃ
SELECT Student_name, Address FROM Student_details WHERE Address='ঢাকা'
UNION ALL
SELECT Teacher_name, Address FROM Teacher_details WHERE Address='ঢাকা'
ORDER BY Address;
উপরের উদাহরণটির ফলাফল নিম্নের ন্যায় দেখাবেঃ
| আইডি | নাম | ঠিকানা |
|---|---|---|
| ১ | ওয়াহিদুল ইসলাম | ঢাকা |
| ২ | মারুফ হোসেন | ঢাকা |
| ৩ | ফারুক আলম | ঢাকা |
| ৪ | মোঃ সাইফুল ইসলাম | ঢাকা |
| ৫ | নাদিমা আক্তার | ঢাকা |
NULL ভ্যালু দ্বারা যে সকল কলামে কোনো তথ্য থাকে না তাদেরকে বুঝায়। ডিফল্টভাবে একটি টেবিলের কলামে NULL ভ্যালু থাকতে পারে। এজন্য টেবিল তৈরির সময়েই কলামে NULL ভ্যালু ডিফাইন করে দিতে হবে।
একটি টেবিলের কোনো কলাম যদি ঐচ্ছিক(optional) হয় তাহলে আমরা ঐ কলামে কোনো ভ্যালু যোগ করা ছাড়াই নতুন রেকর্ড ইনসার্ট করতে অথবা পুরনো রেকর্ডকে আপডেট করতে পারি। এক্ষেত্রে ঐ ফিল্ডটি NULL ভ্যালু সংরক্ষন করবে।
অন্যান্য ভ্যালু হতে NULL ভ্যালুকে ভিন্নভাবে দেখা হয়। অজানা এবং প্রযোজ্যনহে এমন ভ্যালুর জন্য NULL ব্যবহার করা হয়।
বিঃদ্রঃ আপনি NULL এবং শূণ্য(0) এর মধ্যে তুলনা করতে পারবেন না কারণ তারা সমান এবং সমজাতীয় নয়।
নিচের "Student_details" টেবিলে লক্ষ্য করুনঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
ধরুন "Student_details" টেবিলের "ঠিকানা(Address)" কলামটি ঐচ্ছিক। আমরা যদি "ঠিকানা(Address)" কলামে কোন ভ্যালু ছাড়াই একটি রেকর্ড তৈরি করি তাহলে "ঠিকানা(Address)" কলামের ভ্যালু NULL হবে।
আপনি NULL ভ্যালুকে কম্প্যারিজন(comparison) অপারেটর( =, <, <> ) এর মাধ্যমে যাচাই করতে পারবেন না।
বরং এর পরিবর্তে আপনি IS NULL এবং IS NOT NULL অপারেটর ব্যবহার করতে পারেন।
আমরা "ঠিকানা(Address)" কলামের NULL ভ্যালুযুক্ত রেকর্ডকে IS NULL অপারেটর ব্যবহার করে সিলেক্ট করতে পারিঃ
SELECT Roll_number, Student_name, Address
FROM Student_details
WHERE Address IS NULL;
ফলাফলঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ঠিকানা |
|---|---|---|
| ১০৪ | ইয়াসিন হোসেন | |
| ১০৫ | ফরহাদ উদ্দিন | |
| ১০৯ | ওয়াহিদুল ইসলাম |
পরামর্শঃ NULL ভ্যালু খুঁজে বের করার জন্য সব সময় IS NULL অপারেটর ব্যবহার করুন।
"ঠিকানা(Address)" কলামে NULL ভ্যালু নেই এমন রেকর্ডকে সিলেক্ট করতে আমরা IS NOT NULL অপারেটর ব্যবহার করতে পারিঃ
SELECT Roll_number, Student_name, Address
FROM Student_details
WHERE Address IS NOT NULL;
ফলাফলঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ঠিকানা |
|---|---|---|
| ১০১ | তামজীদ হাসান | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | চাঁদপুর |
পরবর্তীতে আমরা ISNULL(), NVL(), IFNULL() এবং COALESCE() ফাংশন সম্পর্কে জানবো।
নিম্নের "Student_result" টেবিলটি লক্ষ্য করুনঃ
| আইডি নং | রোল নাম্বার | লিখিত নাম্বার | এমসিকিউ নাম্বার | ফলাফল |
|---|---|---|---|---|
| ১ | ১০১ | ৫১ | ৩৬ | A+ |
| ২ | ১০২ | ৫২ | ৩৫ | A+ |
| ৩ | ১০৩ | ৫৪ | ৩০ | A+ |
| ৪ | ১০৪ | ৫০ | ৩১ | A+ |
| ৫ | ১০৫ | ৪৯ | ৩৩ | A+ |
ধরুন "এমসিকিউ নাম্বার(Mcq_number)" কলামটি ঐচ্ছিক এবং ইহা Null ভ্যালু ধারণ করতে পারে।
নিম্নের উদাহরণটি লক্ষ করুনঃ
SELECT Roll_number, (Written_number+Mcq_number)
FROM Student_result;
উপরের উদাহরণে যদি "এমসিকিউ নাম্বার(Mcq_number)" কলামের ভ্যালু Null হয় তাহলে ফলাফলও Null হবে।
Null এর ভ্যালু নির্ধারণের জন্য মাইক্রোসফট ISNULL() ফাংশন ব্যবহার করে।
NVL(), IFNULL() এবং COALESCE() ফাংশন গুলোও একই কাজ করে।
Null ফাংশন ব্যবহারের উদ্দেশ্য হলো আমরা Null ভ্যালুর পরিবর্তে 0(শূন্য) পেতে চাই।
ISNULL() ফাংশন ব্যবহার করলে "এমসিকিউ নাম্বার(Mcq_number)" কলামের কোন মান Null হলেও হিসাব-নিকাশে কোন সমস্যা হবে না, কারন প্রতিটি Null ভ্যালুর জন্য ISNULL() ফাংশনটি একটি 0(শূন্য) রিটার্ন করবেঃ
MS Access এর জন্য
SELECT Roll_number, (Written_number+IIF(ISNULL(Mcq_number),0,Mcq_number))
FROM Student_result;
SQL Server এর জন্য
SELECT Roll_number, (Written_number+ISNULL(Mcq_number,0))
FROM Student_result;
ওরাকলে কোনো ISNULL() ফাংশন নেই। ওরাকলে আমরা ISNULL() এর পরিবর্তে NVL() ফাংশনটি ব্যবহার করবোঃ
Oracle এর জন্য
SELECT Roll_number, (Written_number+NVL(Mcq_number,0))
FROM Student_result;
MySQL এ ISNULL() ফাংশন আছে। তবুও ইহা মাইক্রোসফট ISNULL() ফাংশনের চেয়ে একটু ভিন্ন ভাবে কাজ করে।
MySQL এ আমরা IFNULL() ফাংশনটি ব্যবহার করবোঃ
MySQL এর জন্য
SELECT Roll_number, (Written_number+IFNULL(Mcq_number,0))
FROM Student_result;
অথবা আমরা COALESCE() ফাংশনটি ব্যবহার করতে পারিঃ
SELECT Roll_number, (Written_number+COALESCE(Mcq_number,0))
FROM Student_result;অস্থায়ীভাবে একটি টেবিল বা একটি কলামের নাম পরিবর্তন করতে SQL alias ব্যবহার করা হয়।
SQL alias এর মাধ্যমে ডাটাবেজ টেবিল অথবা টেবিল কলামের জন্য একটি অস্থায়ী নাম দেওয়া হয়। Alias ব্যবহার করলে ডেটাবেজের মূল টেবিল বা কলামের নামের কোন পরিবর্তন হয় না।
সাধারনত কলামের নাম-সমূহকে অধিক পাঠযোগ্য করে তোলার জন্য alias তৈরি করা হয়।
SELECT name_of_column AS name_of_alias
FROM name_of_table;
SELECT name_of_column's
FROM name_of_table AS name_of_alias;
AS কীওয়ার্ড এর ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|
| ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়া হয়েছেঃ
| রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|
| ১০১ | ৮৯% | ০১-১১-২০১৫ |
| ১০২ | ৯১% | ০১-১১-২০১৫ |
| ১০৩ | ৮০% | ০১-১১-২০১৫ |
| ১০৪ | ৭৫% | ০২-১১-২০১৫ |
| ১০৫ | ৭৭% | ০২-১১-২০১৫ |
নিচের SQL স্টেটমেন্টটিতে আমরা দুইটি alias ব্যবহার করবো। একটি "Student_name" কলামের জন্য এবং অন্যটি "Address" কলামের জন্য।
বিঃদ্রঃ যদি কলাম নামে স্পেস থাকে তাহলে ডাবল উদ্ধৃতি("") অথবা স্কোয়ার ব্যাকেট ব্যবহার করতে হবেঃ
উদাহরণ
SELECT Student_name AS "শিক্ষার্থীর নাম", Address AS "ঠিকানা"
FROM Student_details;
ফলাফলঃ
| শিক্ষার্থীর নাম | ঠিকানা |
|---|---|
| তামজীদ হাসান | চাঁদপুর |
| মিনহাজুর রহমান | চাঁদপুর |
| মোঃ সবুজ হোসেন | চাঁদপুর |
| ইয়াসিন হোসেন | চাঁদপুর |
| ফরহাদ উদ্দিন | চাঁদপুর |
নিচের SQL স্টেটমেন্টটিতে আমরা Institute এবং Address কলাম দুটি একত্রিত করে "প্রতিষ্ঠানের ঠিকানা(Institute_address)" নামে একটি নতুন alias তৈরি করবোঃ
উদাহরণ
SELECT Student_name, Institute+', '+Address AS Institute_address
FROM Student_details;
ফলাফলঃ
| শিক্ষার্থীর নাম | প্রতিষ্ঠানের ঠিকানা |
|---|---|
| তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয়, চাঁদপুর |
| মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয়, চাঁদপুর |
| মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয়, চাঁদপুর |
| ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয়, চাঁদপুর |
| ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয়, চাঁদপুর |
বিঃদ্রঃ উপরের SQL স্টেটমেন্টটি MySQL এ ঠিকমত কাজ করানোর জন্য নিম্নের কোড অনুসরন করুনঃ
SELECT Student_name, CONCAT(Institute,', ',Address)
AS Institute_address
FROM Student_details;
নিম্নের SQL স্টেটমেন্টটি "Student_details" এবং "Student_attendance" টেবিল থেকে "রোল নাম্বার, শিক্ষার্থির নাম" এবং "ভর্তির তারিখ" কলামের রেকর্ড সিলেক্ট করেবে । কিন্তু শুধুমাত্র "শিক্ষার্থির নাম(Student_name)" কলামের "তামজীদ হাসান" এর রেকর্ড গুলো দেখাবেঃ
উদাহরণ
SELECT Sd.Roll_number, Sd.Student_name, Sa.Admission_date
FROM Student_details AS Sd, Student_attendance AS Sa
WHERE Sd.Student_name = "তামজীদ হাসান" AND Sd.Roll_number=Sa.Roll_number;
ফলাফলঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
alias ব্যতিত একই SQL স্টেটমেন্টঃ
উদাহরণ
SELECT Student_details.Roll_number, Student_details.Student_name, Student_attendance.Admission_date
FROM Student_details, Student_attendance
WHERE Student_details.Student_name = "তামজীদ হাসান" AND Student_details.Roll_number=Student_attendance.Roll_number;
ফলাফলঃ
| রোল নাম্বার | শিক্ষার্থীর নাম | ভর্তির তারিখ |
|---|---|---|
| ১০১ | তামজীদ হাসান | ০১-১১-২০১৫ |
CREATE INDEX স্টেটমেন্ট ব্যবহার করে টেবিলের মধ্যে ইনডেক্স তৈরি করা হয়। একটি টেবিলের সম্পূর্ন তথ্য না পড়েই, ইনডেক্সের সাহায্য ডাটাবেজ থেকে দ্রুত তথ্য খুঁজে পাওয়া যায়।
একটি ডাটাবেজ টেবিল থেকে দ্রুত এবং দক্ষতার সাথে তথ্য খুঁজে বের করার জন্য ইনডেক্স তৈরি করা হয়। ইউজাররা ইনডেক্স দেখতে পায় না, এগুলো শুধুমাত্র দ্রুত তথ্য কুয়েরি/খুঁজে বের করার জন্য ব্যবহার করা হয়।
বিঃদ্রঃ সাধারন টেবিলের তথ্য আপডেট করতে যে সময় লাগে ইনডেক্স যুক্ত টেবিলের তথ্য আপডেট করতে তার চেয়ে বেশী সময় লাগে। সুতরাং সচারচর সার্স করতে হবে এমন কলামের জন্য ইনডেক্স তৈরি করুন।
CREATE INDEX name_of_index
ON name_of_table (name_of_column);
ইনডেক্স টেবিলে ডুপ্লিকেট ভ্যালু গ্রহণযোগ্য।
CREATE UNIQUE INDEX name_of_index
ON name_of_table (name_of_column);
ইউনিক ইনডেক্স টেবিলে ডুপ্লিকেট ভ্যালু গ্রহণযোগ্য নহে।
বিঃদ্রঃ ইনডেক্স তৈরির সিনট্যাক্স বিভিন্ন ডেটাবেজে বিভিন্ন রকম হয়। সুতরাং ইনডেক্স তৈরির পূর্বে আপনার ডেটাবেজের জন্য ইনডেক্স তৈরির সিনট্যাক্সটি দেখে নিন।
CREATE INDEX স্টেটমেন্টের ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিলের "শিক্ষার্থীর নাম(Student_name)" কলামে "Sn_Index" নামে একটি ইনডেক্স তৈরি করবেঃ
CREATE INDEX Sn_Index
ON Student_details (Student_name);
আপনি যদি দুইটি কলামের জন্য একটি ইনডেক্স তৈরি করতে চান তাহলে নিম্নের SQL স্টেটমেন্টটি দেখুনঃ
CREATE INDEX Sa_Index
ON Student_details (Institute, Address);VIEW হল একটি ভার্চুয়াল টেবিল। এই অধ্যায়ে আমরা একটি VIEW তৈরী, আপডেট এবং ডিলেট করা শিখবো।
SQL এ VIEW একটি ভার্চুয়াল টেবিল যা SQL স্টেটমেন্টের রেজাল্ট-সেট এর উপর ভিত্তিকরে গঠিত হয়।
একটি বাস্তব টেবিলের ন্যায় VIEW টেবিলেও কলাম এবং সারি থাকে। ডেটাবেজের অন্তর্ভূক্ত এক বা একধিক টেবিলের কলাম VIEW টেবিলের কলাম হয়।
তথ্য দেখা এবং প্রদর্শনীর জন্য আপনি VIEW টেবিলে SQL ফাংশন, WHERE এবং JOIN স্টেটমেন্ট ব্যবহার করতে পাবেন।
CREATE VIEW name_of_view AS
SELECT name_of_column's
FROM name_of_table
WHERE condition;
বিঃদ্রঃ VIEW সর্বদাই আপনাকে আপডেট তথ্য দেখাবে! যখন কোনো ইউজার VIEW কুয়েরি করে তখন ডাটাবেজ ইঞ্জিন SQL VIEW স্টেটমেন্ট ব্যবহার করে পুনরায় তথ্য তৈরি করে।
আপনি যদি আমাদের নমুনা ডেটাবেজটি দেখে থাকেন তাহলে নিশ্চয়ই দেখবেন যে, ডিফল্ট ভাবে ইহার বিভিন্ন ধরনের ভিউ আছে।
আমরা "Student_details" টেবিল থেকে "বর্তমান শিক্ষার্থীর তালিকা(Current Student List)" এর জন্য একটি VIEW তৈরী করবো। যেখানে বর্তমানে প্রাপ্ত সকল শিক্ষার্থীর তথ্য থাকবে। এর জন্য নিম্নের SQL স্টেটমেন্টটি ব্যবহার করুনঃ
CREATE VIEW [Current Student List] AS
SELECT Roll_number, Student_name
FROM Student_details
WHERE Discontinued=No;
উপরের VIEW কে আমরা নিম্নের ন্যায়ও কুয়েরি করতে পারিঃ
SELECT * FROM [Current Student List]
নিম্নের SQl স্টেটমেন্ট ব্যবহার করে অন্য একটি VIEW এ আমরা আমাদের নমুনা ডেটাবেজের "Student_details" টেবিলের সকল শিক্ষার্থীকে তাদের রোল নাম্বারের ক্রমানুসারে দেখাবোঃ
CREATE VIEW [Student Serialized by Roll] AS
SELECT Roll_number, Student_name
FROM Student_details
WHERE Roll_number>(SELECT AVG(Roll_number) FROM Student_details);
উপরের VIEW কে আমরা নিম্নের ন্যায়ও কুয়েরি করতে পারিঃ
SELECT * FROM [Student Serialized by Roll]
আমাদের নমুনা ডেটাবেজের অন্য একটি VIEW -এ আমরা দেখবো "Student_details" টেবিলের সকল শিক্ষার্থীদের মধ্যে কারা ২০১৫ সালে ভর্তি হয়েছিল। এই VIEW এ যে তথ্যগুলো দেখানো হয়েছে তা অন্য একটি VIEW "Student Details 2015" থেকে নেওয়া হয়েছেঃ
CREATE VIEW [Admitted Student 2015] AS
SELECT Roll_number, Student_name
FROM [Student Details 2015]
Group BY Student_name;
উপরের VIEW কে আমরা নিম্নের ন্যায়ও কুয়েরি করতে পার
SELECT * FROM [Student Details 2015]
কুয়েরিতে আমরা শর্তও যোগ করতে পারিঃ
SELECT * FROM [Student Details 2015]
WHERE Student_name='তামজীদ হাসান'
নিম্নবর্তী সিনট্যাক্সটি ব্যবহার করে VIEW আপডেট করতে পারিঃ
CREATE অথবা REPLACE VIEW সিনট্যাক্সCREATE OR REPLACE VIEW name_of_view AS
SELECT name_of_column's
FROM name_of_table
WHERE condition
এখন আমরা "বর্তমান শিক্ষার্থীর তালিকায়(Current Student List)" "জন্মদিন(Birthday)" কলামটি যোগ করবো। আমরা নিম্নবর্তী সিনট্যাক্স দ্বারা VIEW আপডেট করবোঃ
CREATE OR REPLACE VIEW [Current Student List] AS
SELECT Roll_number, Student_name, Birthday
FROM Student_details
WHERE Discontinued=No;
আপনি DROP VIEW কমান্ডের মাধ্যমে একটি VIEW ডিলেট করতে পারেন।
DROP VIEW name_of_viewAggregate ফাংশন এর সাথে WHERE কিওয়ার্ড ব্যবহার করা যেত না বলে SQL এ HAVING clause যোগ করা হয়েছিল।
SELECT name_of_column, aggregate_function(name_of_column)
FROM name_OF_table
WHERE name_of_column operator value
GROUP BY name_of_column
HAVING aggregate_function(name_of_column) operator value;
HAVING Clause এর ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিচের অংশটি "Student_attendance" টেবিল থেকে নেওয়াঃ
| আইডি নং | রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|---|
| ১ | ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ২ | ১০২ | ৯১ | ০১-১১-২০১৫ |
| ৩ | ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ৪ | ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ৫ | ১০৫ | ৭৭ | ০২-১১-২০১৫ |
নিচের SQL স্টেটমেন্টটি যে সকল শিক্ষার্থী ৭৫ শতাংশ উপস্থিত ছিল তাদেরকে সিলেক্ট করবে।
উদাহরণ
SELECT Student_details.Student_name, Student_attendance.Roll_number, COUNT(Student_attendance.Attendance) AS Attendance
FROM (Student_attendance
INNER JOIN Student_details
ON Student_attendance.Roll_number=Student_details.Roll_number)
GROUP BY Student_name
HAVING COUNT(Student_attendance.Attendance) > 75;
ফলাফল
| রোল নাম্বার | শিক্ষার্থীর নাম | শতকরা উপস্থিতি |
|---|---|---|
| ১০১ | তামজীদ হাসান | ৮৯% |
| ১০২ | মিনহাজুর রহমান | ৯১% |
| ১০৩ | মোঃ সবুজ হোসেন | ৮০% |
| ১০৪ | ইয়াসিন হোসেন | ৮৭% |
| ১০৫ | ফরহাদ উদ্দিন | ৮৫% |
এখন আমরা খুজে বের করবো, শিক্ষার্থী "তামজীদ হসান" অথবা "মিনহাজুর রহমান" শতকরা ৯০ শতাংশ উপস্থিত ছিল কি না।
SELECT Student_details.Student_name, Student_attendance.Roll_number, COUNT(Student_attendance.Attendance) AS Attendance
FROM (Student_attendance
INNER JOIN Student_details
ON Student_attendance.Roll_number=Student_details.Roll_number)
WHERE Student_name="তামজীদ হসান" OR Student_name="মিনহাজুর রহমান"
GROUP BY Student_name
HAVING COUNT(Student_attendance.Attendance) > 90;
ফলাফল
| রোল নাম্বার | শিক্ষার্থীর নাম | শতকরা উপস্থিতি |
|---|---|---|
| ১০২ | মিনহাজুর রহমান | ৯১% |
একটি স্ট্রিং এর মধ্যে যেকোন ক্যারেক্টার এর বিকল্প হিসাবে ওয়াইল্ডকার্ড(wildcard) ক্যারেক্টার ব্যবহার করা হয়।
SQL এ LIKE অপারেটরের সাথে ওয়াইল্ডকার্ড ক্যারেক্টার ব্যবহার করা হয়। SQL ওয়াইল্ডকার্ড ব্যবহার করে টেবিলের মধ্য থেকে ডেটা সার্চ করা হয়।
নিম্নে SQL ওয়াইল্ডকার্ড গুলো বর্ণনা করা হলঃ
| ওয়াইল্ডকার্ড | বর্ণনা |
|---|---|
% | শূন্য বা অধিক ক্যারেক্টার খুঁজে করে। |
_ | একটি একক ক্যারেক্টার খুঁজে বের করে। |
[charlist] | এক সেট অথবা নির্দিষ্ট ব্যবধী হতে ক্যারেক্টার খুঁজে বের করে। |
[^charlist] অথবা [!charlist] | বন্ধনীতে উল্লেখিত ক্যারেক্টার ব্যতিত বাকি সকল ক্যারেক্টার খুঁজে বের করে। |
ওয়াইল্ডকার্ড এর ব্যবহার দেখানোর জন্য আমরা আমাদের নমুনা ডেটাবেজ Student ব্যবহার করবো।
নিচের অংশটি "Student_details" টেবিল থেকে নেওয়া হয়েছেঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত যে সকল শব্দ "ঢা" দিয়ে শুরু হয়েছে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE 'ঢা%';
ফলাফলঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ৯ | ১০৯ | ওয়াহিদুল ইসলাম | জাতীয় বিশ্ববিদ্যালয় | ঢাকা |
| ১১ | ১১১ | সৌরভ বনিক | জাতীয় বিশ্ববিদ্যালয় | ঢাকা |
| ১৬ | ১১৬ | মারুফ হোসেন | জাতীয় বিশ্ববিদ্যালয় | ঢাকা |
| ২০ | ১২০ | দেলোয়ার হোসেন | জাতীয় বিশ্ববিদ্যালয় | ঢাকা |
| ২২ | ১২২ | ফারুক আলম | জাতীয় বিশ্ববিদ্যালয় | ঢাকা |
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত যে সকল শব্দে "দপু" প্যাটার্ন থাকবে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE '%দপু%';
ফলাফলঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ১ | ১০১ | তামজীদ হাসান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ২ | ১০২ | মিনহাজুর রহমান | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৩ | ১০৩ | মোঃ সবুজ হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৪ | ১০৪ | ইয়াসিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
| ৫ | ১০৫ | ফরহাদ উদ্দিন | জাতীয় বিশ্ববিদ্যালয় | চাঁদপুর |
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত যে সকল শব্দ যেকোন অক্ষর দিয়ে শুরু হবে এবং এর পরে "জশাহী" প্যাটার্ন থাকবে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE '_ _জশাহী';
"ঠিকানা(Address)" কলামে অবস্থিত যে সকল শব্দ যেকোন অক্ষর দিয়ে শুরু হবে এর পরে "া" এবং এর পরে যেকোনো সংখ্যা এবং এর পরে "শাহী" প্যাটার্ন থাকবে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE '_ া _শাহী';
ফলাফলঃ
| আইডি নং | রোল নাম্বার | শিক্ষার্থীর নাম | প্রতিষ্ঠানের নাম | ঠিকানা |
|---|---|---|---|---|
| ৭ | ১০৭ | মোঃ ফয়সাল ইসলাম | জাতীয় বিশ্ববিদ্যালয় | রাজশাহী |
| ১৪ | ১১৪ | ওমর ফারুক | জাতীয় বিশ্ববিদ্যালয় | রাজশাহী |
| ১৯ | ১১৯ | মোঃ মমিন হোসেন | জাতীয় বিশ্ববিদ্যালয় | রাজশাহী |
| ৩০ | ১৩০ | হেদায়েত উল্লাহ | জাতীয় বিশ্ববিদ্যালয় | রাজশাহী |
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করেবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত শব্দ গুলোর মধ্যে যাদের প্রথম অক্ষর "ঢ" অথবা "র" দিয়ে শুরু হয়ছেে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE '[ঢর]%';
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত শব্দগুলোর মধ্যে যাদের প্রথম অক্ষর "ক" থেকে "চ" এর মধ্যে যেকোন একটি দিয়ে শুরু হয়েছে শুধুমাত্র তাদের দেখাবেঃ
SELECT * FROM Student_details
WHERE Address LIKE '[ক-চ]%';
নিম্নের SQL স্টেটমেন্টটি "Student_details" টেবিল থেকে সকল তথ্য সিলেক্ট করবে, কিন্তু "ঠিকানা(Address)" কলামে অবস্থিত শব্দ গুলোর মধ্যে যাদের প্রথম অক্ষর "ঢ" অথবা "র" দিয়ে শুরু হয়েছে শুধুমাত্র তাদের দেখাবে নাঃ
SELECT * FROM Student_details
WHERE Address LIKE '[!ঢর]%';
অথবা
SELECT * FROM Student_details
WHERE Address NOT LIKE '[ঢর]%';
বিঃদ্রঃ উপরের সকল উদাহণের ক্ষেত্রে বাংলা ক্যারেক্টার সঠিকভাবে কাজ নাও করতে পারে।
তারিখ নিয়ে কাজ করার সময় সবচেয়ে গুরত্বপূর্ণ কাজ হলো আপনি তারিখের যে ফরম্যাট নির্বাচন করেছেন তা যেন আপনার ডেটাবেজ কলামের
dateফরম্যাটের সাথে মিলে। এটা নাহলে আপনি ডেটাবেজে সঠিক ভাবেdateইনপুট করতে পারবেন না।
আপনার date কলামে শুধুমাত্র তারিখ থাকলে কুয়েরি করতে অনেক সহজ হবে। কিন্তু যদি আপনার date কলামে তারিখের পাশাপাশি সময়ও থাকে তাহলে কুয়েরি করা একটু কঠিন হয়ে উঠে।
নিম্নে MySQL এবং SQL Server এর কিছু গুরুত্বপূর্ণ বিল্ট-ইন date ফাংশন এবং তাদের ব্যবহার বর্ণনা করা হলোঃ
নিম্নের তালিকায় MySQL এর কয়েকটি গুরুত্বপূর্ণ বিল্ট-ইন ফাংশন দেওয়া হলঃ
| ফাংশন | বর্ণনা |
|---|---|
NOW() | বর্তমান date এবং time রিটার্ন করবে। |
CURDATE() | বর্তমান date রিটার্ন করবে। |
CURTIME() | বর্তমান time রিটার্ন করবে। |
DATE() | date অথবা date/time এক্সপ্রেশন থেকে শুধুমাত্র date অংশটি নিবে। |
EXTRACT() | date অথবা time যেকোন একটি অংশ রিটার্ন করবে। |
DATE_ADD() | date এ একটি নির্দিষ্ট সময় ব্যবধান যোগ করবে। |
DATE_SUB() | date থেকে একটি নির্দিষ্ট সময় ব্যবধান বিয়োগ করবে। |
DATEDIFF() | দুইটি date এর পার্থক্য রিটার্ন করবে। |
DATE_FORMAT() | date অথবা time কে দেখানোর জন্য বিভিন্ন ফরম্যাট নির্ধারন করবে। |
নিম্নের লিস্টে SQL Server এর কয়েকটি গুরুত্বপূর্ণ বিল্ট-ইন ফাংশন দেওয়া হলঃ
| ফাংশন | বর্ণনা |
|---|---|
GETDATE() | বর্তমান date এবং time রিটার্ন করবে। |
DATEPART() | date অথবা time যেকোন একটি অংশ রিটার্ন করবে। |
DATEADD() | date থেকে একটি নির্দিষ্ট সময় ব্যবধান যোগ/বিয়োগ করবে। |
DATEDIFF() | দুইটি date এর পার্থক্য রিটার্ন করবে। |
CONVERT() | date অথবা time কে দেখানোর জন্য বিভিন্ন ফরম্যাট নির্ধারন করবে। |
MySQL ডেটাবেজে date অথবা date/time এর সিনট্যাক্সঃ
DATE - ফরম্যাটঃ YYYY-MM-DDDATETIME - ফরম্যাটঃ YYYY-MM-DD HH:MI:SSDATETIME - ফরম্যাটঃ YYYY-MM-DD HH:MI:SSYEAR - ফরম্যাটঃ YYYY অথবা YYSQL Server ডেটাবেজে date অথবা date/time এর সিনট্যাক্সঃ
DATE - ফরম্যাটঃ YYYY-MM-DDDATETIME - ফরম্যাটঃ YYYY-MM-DD HH:MI:SSSMALLDATETIME - ফরম্যাটঃ YYYY-MM-DD HH:MI:SSDATETIME - ফরম্যাটঃ একটি ইউনিক নাম্বারবিঃদ্রঃ ডাটবেজে নতুন টেবিল তৈরি করার সময় আপনি কলাম এর জন্য
dateএর টাইপ নির্ধারণ করে দিতে পারবেন!
তারিখের সাথে অন্য কোন উপাদান জড়িত না থাকলে আপনি খুব সহজেই দুইটি তারিখের মধ্যে তুলনা করতে পারেন।
নিম্নলিখিত "Student_attendance" টেবিলটি দেখুনঃ
| আইডি নং | রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|---|
| ১ | ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ২ | ১০২ | ৯১ | ০১-১১-২০১৫ |
| ৩ | ১০৩ | ৮০ | ০১-১১-২০১৫ |
| ৪ | ১০৪ | ৭৫ | ০২-১১-২০১৫ |
| ৫ | ১০৫ | ৭৭ | ০২-১১-২০১৫ |
এখন আমরা "ভর্তির তারিখ(Admission_date)" কলাম থেকে "০১-১১-২০১৫" তারিখের রেকর্ড-সমূহ সিলেক্ট করবো।
উদাহরণ
SELECT * FROM Student_attendance
WHERE Admission_date='০১-১১-২০১৫';
ফলাফলঃ
| আইডি নং | রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|---|
| ১ | ১০১ | ৮৯ | ০১-১১-২০১৫ |
| ২ | ১০২ | ৯১ | ০১-১১-২০১৫ |
| ৩ | ১০৩ | ৮০ | ০১-১১-২০১৫ |
এখন আমরা "Student_attendance" টেবিলের "ভর্তির তারিখ(Admission_date)" কলামে তারিখের সাথে সময়ও যুক্ত করবো।
ধরুন, এখন আমাদের "Student_attendance" টেবিলটি নিম্নের মত দেখাবেঃ
| আইডি নং | রোল নাম্বার | উপস্থিতি | ভর্তির তারিখ |
|---|---|---|---|
| ১ | ১০১ | ৮৯ | ০১-১১-২০১৫ ১১:৩০:২০ |
| ২ | ১০২ | ৯১ | ০১-১১-২০১৫ ১১:৩২:১০ |
| ৩ | ১০৩ | ৮০ | ০১-১১-২০১৫ ১১:৪০:৪৫ |
এখন আমরা যদি উপরের মত একই
SELECTস্টেটমেন্ট ব্যবহার করি তাহলে আমরা কোন ফলাফল পাবো না! কারন এই কুয়েরিটি শুধুমাত্রdateকে সিলেক্ট করবে।বিঃদ্রঃ আপনি যদি আপনার কুয়েরিকে সহজ রাখতে চান তাহলে
dateকলামেtimeকে ভিন্ন কলামে যোগ করুন।
একটি কলাম কোন ধরনের ভ্যালু ধারণ করবে তা ডেটা টাইপের মাধ্যমে ডিফাইন করা হয়।
ডেটাবেজ টেবিলের প্রতিটি কলামের জন্য একটি নাম এবং ডেটা টাইপ বাধ্যতামূলক।
টেবিল তৈরির সময়ে SQL ডেভেলপারদেরকে সিদ্ধান্ত নিতে হয় যে, প্রতিটি টেবিলের কলামে কোন টাইপের ডেটা সংরক্ষিত হবে। প্রতিটি কলামে কোন ধরনের ডেটা থাকবে তা ডেটা টাইপের মাধ্যমে SQL কে বুঝিয়ে দেওয়া হয় এবং এর মাধ্যমে SQL তার সংরক্ষিত ডেটা নিয়ে কিভাবে কাজ করবে তা বুঝতে পারে।
নিচের টেবিলে SQL এর সাধারণ ডেটা টাইপের একটি তালিকা দেওয়া হলঃ
| ডেটা টাইপ | বর্ণনা |
|---|---|
CHARACTER(n) | ক্যারেক্টার স্ট্রিং। n দ্বারা ক্যারেক্টার এর নির্দিষ্ট দৈর্ঘ্য নির্ধারণ করা হয়। |
VARCHAR(n) অথবা CHARACTER VARYING(n) | ক্যারেক্টার স্ট্রিং। n দ্বারা ভ্যারিয়েবলের সর্বোচ্চ দৈর্ঘ্য নির্ধারণ করা হয়। |
BINARY(n) | বাইনারী স্ট্রিং। n দ্বারা এর নির্দিষ্ট দৈর্ঘ্য নির্ধারণ করা হয়। |
BOOLEAN | এর দ্বারা TRUE অথবা FALSE ভ্যালু সংরক্ষন করা হয়। |
VARBINARY(n) অথবা BINARY VARYING(n) | বাইনারী স্ট্রিং। n দ্বারা ভ্যারিয়েবলের সর্বোচ্চ দৈর্ঘ্য নির্ধারণ করা হয়। |
INTEGER(p) | নিউমেরিক ইন্টেজার(দশমিক নয়)। সর্বোচ্চ p সংখ্যা পর্যন্ত নির্ভুলভাবে দেখাবে। |
SMALLINT | নিউমেরিক ইন্টেজার(দশমিক নয়)। সর্বোচ্চ ৫ সংখ্যা পর্যন্ত নির্ভুলভাবে দেখাবে। |
INTEGER | নিউমেরিক ইন্টেজার(দশমিক নয়)। সর্বোচ্চ ১০ সংখ্যা পর্যন্ত নির্ভুলভাবে দেখাবে। |
BIGINT | নিউমেরিক ইন্টেজার(দশমিক নয়)। সর্বোচ্চ ১৯ সংখ্যা পর্যন্ত নির্ভুলভাবে দেখাবে। |
DECIMAL(p,s) | সুনির্দিষ্ট সংখ্যা, নির্ভুলভাবে p পর্যন্ত দেখাবে, স্কেল s । উদাহরনঃ decimal(5,2) একটি সংখ্যা যার দশমিকের পূর্বে ৩টি ডিজিট থাকবে এবং দশমিকের পরে ২টি ডিজিট থাকবে। |
NUMERIC(p,s) | সুনির্দিষ্ট সংখ্যা, নির্ভুলভাবে p পর্যন্ত দেখাবে, স্কেল s । (DECIMAL এর মতই) |
FLOAT(p) | সম্ভাব্য সংখ্যা, আংশিক নির্ভুলভাবে p পর্যন্ত দেখাবে। এই টাইপের জন্য সাইজ আর্গুমেন্টটি একটি সংখ্যা দ্বারা নির্ভুলতা সর্বনিম্ন কত সংখ্যা পর্যন্ত হবে তা নির্দেশ করে। |
REAL | সম্ভাব্য সংখ্যা, ৭ পর্যন্ত আংশিক নির্ভুলভাবে প্রদর্শন করবে।/td> |
FLOAT | সম্ভাব্য সংখ্যা, ১৬ পর্যন্ত আংশিক নির্ভুলভাবে প্রদর্শন করবে। |
DOUBLE PRECISION | সম্ভাব্য সংখ্যা, ১৬ পর্যন্ত আংশিক নির্ভুলভাবে প্রদর্শন করবে। |
DATE | বছর, মাস এবং দিনের ভ্যালু সংরক্ষন করে |
TIME | ঘন্টা, মিনিট এবং সেকেন্ডের ভ্যালু সংরক্ষন করে |
TIMESTAMP | বছর, মাস, দিন, ঘন্টা, মিনিট এবং সেকেন্ডের ভ্যালু সংরক্ষন করে |
INTERVAL | একাধিক ইন্টেজার ফিল্ড এর সংমিশ্রণ যা ব্যবধির উপর ভিত্তিকরে একটি সময়কাল নির্ধারণ করে। |
ARRAY | সেট এর দৈর্ঘ্য এবং ক্রমিকভাবে(ordered) তথ্য সংগ্রহকে বুঝায়set-length এবং ordered কালেকশন |
MULTISET | ভ্যারিয়েবলের দৈর্ঘ্য এবং এলোমেলোভাবে(unorderd) তথ্য সংগ্রহকে বুঝায় |
XML | এক্সএমএল ডেটা সংরক্ষন করে |
আরও দেখুন...

or



